
“[Machine learning is] an extremely happening area,” Debi Mishra (@debipmishra), principal engineering manager at Microsoft’s New England Research and Development Center in Cambridge said in a recent interview. “If you fast forward five or 10 years, its applications are going to be mind-boggling.” [“Machine learning is the next big technological phenomenon, Microsoft engineering exec says,” by Sara Castellanos, Boston Business Journal, 15 May 2014] Mishra told Castellanos (@BosBizSara) that in the near future “machine learning will become a mainstream technology used by businesses and individuals to predict scenarios and make strategic decisions.” Although machine learning may sound like a fairly straight forward concept, James Kobielus (@jameskobielus), a senior program director for product marketing for big data analytics solutions at IBM, notes, “As interest in machine learning has grown, its definition has expanded to include a panoply of techniques for automating knowledge and pattern discovery from fresh data.” [“What’s machine learning? It depends on who you ask,” InfoWorld, 23 June 2014] In a previous article, Kobielus noted, “Machine learning is so pervasive that we can often assume its presence in big data applications without having to specifically call it out. … Machine learning is a tool used in many, if not most, … analytic use cases, but it’s not a use case in itself — in other words, it’s not a specific application domain in its own right.” [“Machine learning floats all boats on big data’s ocean,” InfoWorld, 28 February 2014] That’s the beauty of machine learning; it is a useful tool in almost every area that requires analyzing big data. Nevertheless, Kobielus argues that we shouldn’t make the definition of machine learning so broad that we blur its true value. He rues the fact that some people see the terms “machine learning, data mining, predictive analysis, and advanced analytics as more or less synonymous.” He explains:
“I’m not sure that lumping machine learning with all of these other techniques makes sense. … Machine learning primarily applies to unstructured data, whereas data mining is specific to structured data sets. Also, machine learning, like data mining, is principally concerned with finding diverse patterns in historical data, whereas predictive analysis focuses specifically on finding those predictive patterns that can be tested empirically through gathering of fresh data in the future. And whereas machine learning, data mining, and predictive analysis are all narrowly scoped, advanced analytics is a broader scope that includes them all. It seems to me that machine learning has one foot in data science and the other in computer science.”
An article published by the Etisalat BT Innovation Center (EBTIC) states, “Machine Learning is now quite a matured discipline and captures in general any activity that involves automated learning from data or experience. At the core of ML is the ability of a software or machine to improve the performance of certain tasks through being exposed to data and experiences. [A] typical machine learning model first learns the knowledge from the data it is exposed to and then applies this knowledge to deliver predictions about the new, same type but previously unseen data.” [“Machine Learning on Big DataWhat is machine learning (ML) useful for?” EBTIC, 19 August 2014] The article goes on to note that there are basically three types of machine learning: supervised learning, unsupervised learning, and reinforcement learning. Concerning supervised learning, the article states:
“Supervised learning algorithms use labelled training examples. The input data and the target outputs are given explicitly for the model to learn the mapping or function between them. Once this is captured the model then uses the learned mapping and the new unseen input data to predict their outputs. Within [the] supervised learning family we can further distinguish between classification models which focus on prediction of discrete (categorical) outputs or regression models which predict [continuous] outputs. Among [the] large number of models reported in the literature [are] linear and nonlinear density based classifiers, decision trees, naïve Bayes, support vector machines, neural networks and nearest neighbour are the most frequently cited and applied in practical applications.”
In a paper discussing supervised machine learning, Professor Sotiris B. Kotsiantis offers the following flowchart which depicts how the process of supervised machine learning is applied to a real-world problem. [“Supervised Machine Learning: A Review of Classification Techniques,” Informatica 31, 2007]
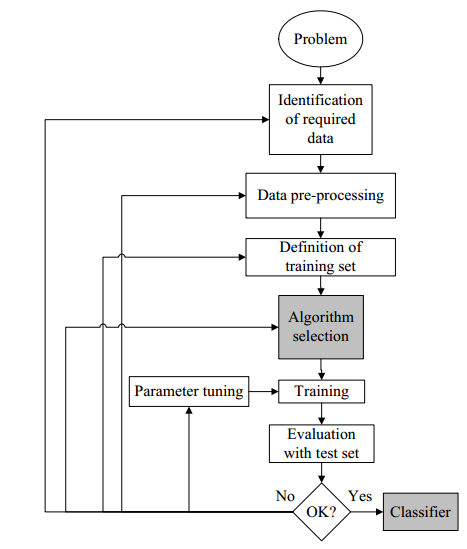
Kotsiantis concludes, “The key question when dealing with ML classification is not whether a learning algorithm is superior to others, but under which conditions a particular method can significantly outperform others on a given application problem.” Concerning the subject of unsupervised machine learning, the EBTIC article states, “Unsupervised learning, typically referred to as clustering, is concerned with recognizing natural grouping among the data, i.e., separating similar from dissimilar data based on multidimensional data.” Dr. Robert Gentleman, a Senior Director of Bioinformatics at Genentech, and Dr. Vincent J. Carey, an Associate Professor in the Department of Medicine at Harvard Medical School, write, “Unsupervised machine learning is also sometimes referred to as class discovery.” [“Unsupervised Machine Learning,” Chapter 10 in Bioconductor Case Studies, by Florian Hahne, Wolfgang Huber, Robert Gentleman, Seth Falcon, Springer, 15 August 2008] They continue:
“One of the major differences between unsupervised machine learning and supervised machine learning is that there is no training set for the former and hence, no obvious role for cross-validation. A second important difference is that although most clustering algorithms are phrased in terms of an optimality criterion there is no guarantee that the globally optimal solution has been obtained. … The prerequisites to performing unsupervised machine learning are the selection samples, or items to cluster, the selection of features to be used in the clustering, the choice of similarity metric for the comparison of samples, and the choice of an algorithm to use.”
Concerning the final type of machine learning — reinforcement learning — the EBTIC article states: “Reinforcement learning lies somewhat in between supervised and unsupervised learning in a sense that learning is not done on the fully labelled or evaluated data but a hint in a form of local reward is provided to every actionable data.” The article continues:
“The objective of the reinforcement learning is to maximise the long term reward through exploration and learning the optimal action policy in response to the environmental data. Reinforcement learning found prime applications in robotics, agent technologies and many complex exploration systems requiring continuous response to the changing environment while maximising strategic longer-term objectives.”
In an introduction to reinforcement machine learning at the Reinforcement Warehouse, it states, “The possible applications of Reinforcement Learning are abundant, due to the genericness of the problem specification. As a matter of fact, a very large number of problems in Artificial Intelligence can be fundamentally mapped to a decision process. This is a distinct advantage, since the same theory can be applied to many different domain specific problems with little effort. In practice, this ranges from controlling robotic arms to finding the most efficient motor combination, to robot navigation where collision avoidance behaviour can be learnt by negative feedback from bumping into obstacles. Logic games are also well-suited to Reinforcement Learning, as they are traditionally defined as a sequence of decisions: games such as poker, backgammon, Othello, [and] chess have been tackled more or less successfully.”
Castellanos notes that there are a number of practical applications for the various models of machine learning, including: “A grocery store could use machine learning to determine how many bottles of ketchup could be sold each week to better plan inventory. A small business could use machine learning to reward customers that are likely to be repeat customers; and a Web service could use the technology to predict which customers are likely to end subscriptions so the company can reach out to them proactively.” Because machine learning has such potential utility for things ranging “from speech and facial recognition to clickstream processing, search-engine optimization, and recommendation engines,” Kobielus calls it “sense-making analytics.” He predicts, “The disparate disciplines under this umbrella will continue to cross-fertilize in innovative ways that will stretch every data scientist’s thinking as well as the terminology they use to define machine learning.”

