
Artificial intelligence (AI) gets a lot of press even though it is primarily an aspirational umbrella term under which rest a number of technologies. Anthony Bradley (@BradleyAnthonyJ), a Group Vice President in Gartner’s Technology and Service Provider research practice, insists, “Artificial intelligence is, at its core, a marketing term.”[1] He adds, “It is a brilliant marketing term as inaccurate as it is prevalent. … The term has captured people’s imagination for over 60 years.” Eric Siegel (@predictanalytic), a former computer science professor at Columbia University, agrees that AI is more hype than substance. He writes, “A.I. is a big fat lie. Artificial intelligence is a fraudulent hoax — or in the best cases it’s a hyped-up buzzword that confuses and deceives.”[2] He goes on to note that machine learning (ML) is a more precise term. And, he adds, “Machine learning is genuinely powerful and everyone oughta be excited about it.” What makes machine learning powerful is algorithms. As the staff at the Institute of Chartered Accountants in England and Wales (ICAEW) notes, “Machine learning [is] the process whereby a computer learns future responses through data analysis via an algorithm.”[3] The four primary machine learning techniques are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning.[4]
The Power of Algorithms
Data journalist Nick Thieme (@FurrierTranform) explains, “Algorithms — the chunks of code that allow programs to sort, filter and combine data, among other things — are the standard tools of modern computing. Like tiny gears inside a watch, algorithms execute well-defined tasks within more complicated programs. They’re ubiquitous, and in part because of this, they’ve been painstakingly optimized over time.”[5] Tech journalist Madhurjya Chowdhury explains that there is not simply one type of machine learning algorithm. He writes, “Machine learning is a catch-all phrase for a collection of strategies and technologies that assist computers in learning and adapting on their own. Machine learning techniques assist AI in learning without explicitly programming the intended action. The machine learning algorithm anticipates and performs tasks completely based on the learned pattern rather than a predetermined program command by learning a structure from sample inputs.”[6]
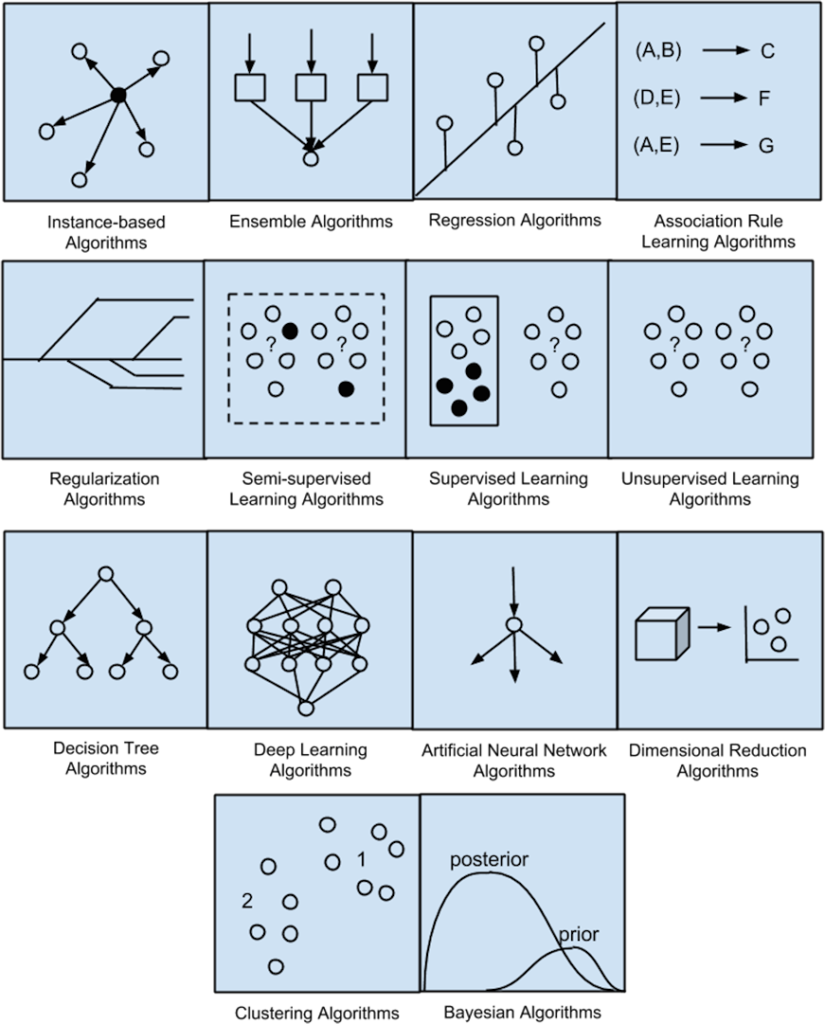
To achieve the desired benefits from machine learning algorithms, you need to know what it is you are trying to accomplish. Chowdhury explains machine learning models can be grouped based on the type of tasks to which they are being applied. According to Chowdhury there are five basic model groups: classification models; regression models; clustering models; dimensionality reduction models, and deep learning models. He provides a brief description of each grouping.
1. Classification Models. Chowdhury explains, “Classification in ML is the job of predicting the type or class of an item from a limited set of possibilities. The categorization output variable is usually a category variable. Predicting whether an email is spam or not, is an example of a classic binary classification job.” Common algorithms used in classification models include: Nearest Neighbor; Naive Bayes; Logistic Regression; Support Vector Machines (SVM); Decision Tree; and Ensembles.
2. Regression Models. “Learning regression,” Chowdhury writes, “has a set of issues in the machine language, where the outcome variable can take continuous variables. Calculating the price of an airline [ticket], for example, is a common regression task.” Common algorithms used in regression models include: Linear Regression; Lasso Regression; Ridge Regression; SVM regression; Ordinary Least Squares Regression (OLSR); Stepwise Regression; Multivariate Adaptive Regression Splines (MARS); Locally Estimated Scatterplot Smoothing (LOESS); and Decision Tree Regression.
3. Clustering. Machine learning is great for recognizing patterns, including clustering. Chowdhury explains, “Clustering, in a nutshell, is the problem of grouping related items together. It aids in the automated identification of comparable items without the need for operator involvement.” Common clustering algorithms include: K means; K means++; K medoids; Agglomerative clustering; and Density-Based Spatial Clustering of Applications with Noise (DBSCAN).
4. Dimensionality Reduction. According to Chowdhury, “The number of predictor factors used to estimate the independent variable or objective is referred to as dimensionality. The number of variables in real-world datasets is frequently excessive. Overfitting is also a problem when there are too many variables in the models. In actuality, not all of these high sets of variables contribute equally to the objective, and in many circumstances, we can actually conserve variances with a smaller number of variables.” Common dimension reduction algorithms include: Principal Component Analysis (PCA); T-distributed Stochastic Neighbor Embedding (t-SNE); and SVD.
5. Deep Learning. A lot of machine learning articles focus on deep learning. Chowdhury explains, “Deep learning is a branch of machine learning that focuses on neural networks.” Common neural network algorithms include: Multi-Layer Perceptron (MLP); Convolution Neural Networks; Recurrent Neural Networks; Back-Propagation; Stochastic Gradient Descent; Hopfield Network; and Radial Basis Function Network (RBFN).
The list of algorithms mentioned above is, by no means, exhaustive. That’s why it’s so important to do your homework before starting a machine learning project. Getting the model right is critical to getting the right results.
Choosing the Right Algorithms
Yogita Kinha Singh, an Associate Managing Consultant at Mastercard, observes, “There’s no free lunch in machine learning. So, determining which algorithm to use depends on many factors from the type of problem at hand to the type of output you are looking for.”[7] Choosing the right algorithms depends on a number of factors. As Singh notes, “There is no straightforward and sure-shot answer to the question: How do I choose the right machine learning algorithm? The answer depends on many factors like the problem statement and the kind of output you want, type and size of the data, the available computational time, number of features, and observations in the data, to name a few.” She suggests a few things to consider when selecting algorithms. They are:
1. Size of the Training Data. Generally speaking, the more data you have the better the results you’ll obtain. Singh writes, “Many a time, the availability of data is a constraint. So, if the training data is smaller or if the dataset has a fewer number of observations and a higher number of features like genetics or textual data, choose algorithms with high bias/low variance like Linear regression, Naïve Bayes, or Linear SVM. If the training data is sufficiently large and the number of observations is higher as compared to the number of features, one can go for low bias/high variance algorithms like KNN, Decision trees, or kernel SVM.”
2. Accuracy and/or Interpretability of the Output. One oft-heard complaint about AI systems is that users have no idea how the computer came up with its responses. Black box results undermine trust. Singh writes, “Accuracy of a model means that the function predicts a response value for a given observation, which is close to the true response value for that observation. A highly interpretable algorithm (restrictive models like Linear Regression) means that one can easily understand how any individual predictor is associated with the response while the flexible models give higher accuracy at the cost of low interpretability.”
3. Speed or Training Time. Business today is conducted a computer speed. So the faster a result can be obtained the better. Singh notes, “Higher accuracy typically means higher training time. Also, algorithms require more time to train on large training data. In real-world applications, the choice of algorithm is driven by these two factors predominantly. Algorithms like Naïve Bayes and Linear and Logistic regression are easy to implement and quick to run. Algorithms like SVM, which involve tuning of parameters, Neural networks with high convergence time, and random forests, need a lot of time to train the data.”
4. Linearity. You’ve probably heard the phrase “making assumptions makes an ‘ass’ out of ‘u’ and ‘me.” Singh writes, “Many algorithms work on the assumption that classes can be separated by a straight line (or its higher-dimensional analog). Examples include logistic regression and support vector machines. Linear regression algorithms assume that data trends follow a straight line. If the data is linear, then these algorithms perform quite good. However, not always is the data is linear, so we require other algorithms which can handle high dimensional and complex data structures. … The best way to find out the linearity is to either fit a linear line or run a logistic regression or SVM and check for residual errors. A higher error means the data is not linear and would need complex algorithms to fit.”
5. Number of Features. Singh explains, “The dataset may have a large number of features that may not all be relevant and significant. For a certain type of data, such as genetics or textual, the number of features can be very large compared to the number of data points. A large number of features can bog down some learning algorithms, making training time unfeasibly long.”
Because selecting the right algorithm can be difficult, at Enterra Solutions® we use Massive Dynamics™ Representational Learning Machine™ (RLM). The RLM helps determine what type of analysis is best-suited for the data involved in a high-dimensional environment and it accomplishes this in a “glass box” rather than “black box” fashion (i.e., it makes decisions explainable).
Concluding Thoughts
Singh concludes there are three main points to consider when trying to solve a new problem. They are:
• Define the problem. What is the objective of the problem?
• Explore the data and familiarize yourself with the data.
• Start with basic models to build a baseline model and then try more complicated methods.
She adds, “Having said that, always remember that ‘better data often beats better algorithms.’ … Equally important is designing good features. Try a bunch of algorithms and compare their performances to choose the best one for your specific task. Also, try ensemble methods as they generally provide much better accuracy.” Chowdhury agrees with that approach. He concludes, “It is usually better to start with the simplest model suited to the problem and progressively raise the complexity through thorough parameter tuning and cross-validation. In the realm of data science, there is a saying that goes, ‘Cross-validation is more reliable than domain expertise’.”
Footnotes
[1] Anthony Bradley, “What is AI – Really? Looking Behind the Hype,” Gartner, 8 February 2022.
[2] Eric Siegel, “Why A.I. is a big fat lie,” Big Think, 23 January 2019.
[3] Staff, “The possibilities and limitations of machine learning,” The Institute of Chartered Accountants in England and Wales, 21 March 2022.
[4] To learn more, see Stephen DeAngelis, “What Business Leaders Need to Know About Machine Learning in 2022,” Enterra Insights, 9 February 2022.
[5] Nick Thieme, “Machine Learning Reimagines the Building Blocks of Computing,” Quanta Magazine, 15 March 2022.
[6] Madhurjya Chowdhury, “Which Machine Learning Model is the Best?” Analytics Insight, 3 March 2022.
[7] Yogita Kinha Singh, “An Easy Guide to Choose the Right Machine Learning Algorithm,” KD Nuggets, 17 February 2022.

